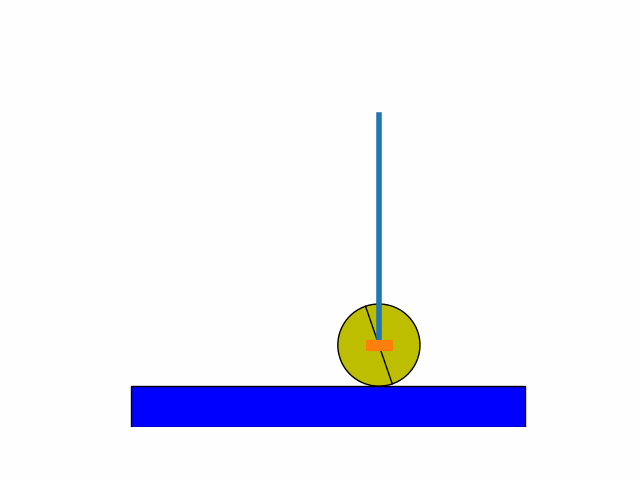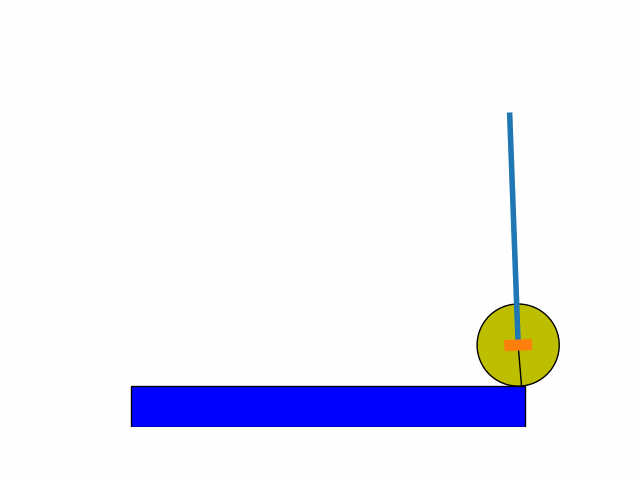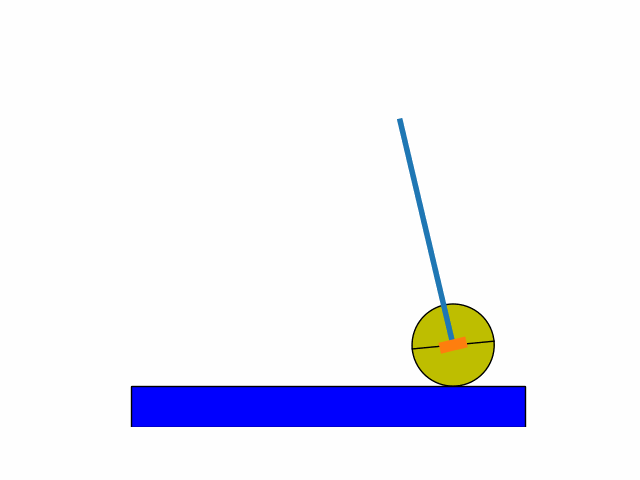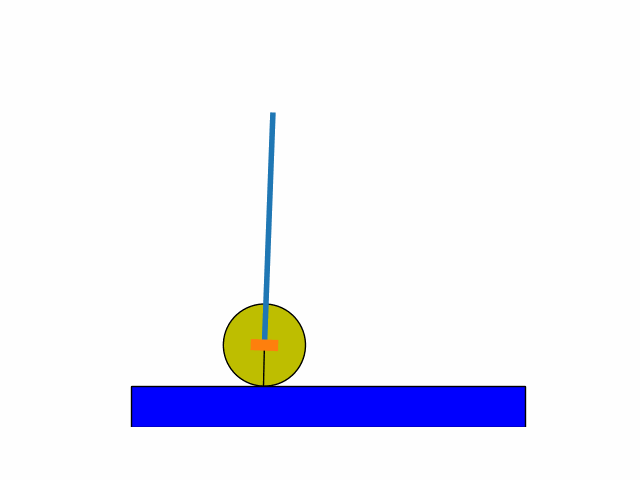
This was inspired from a Stanford CS229 2018 problem set. Using an already defined finite-state inverted pendulum model:
- I used numpy to estimate the world model (transition probabilities and rewards)
- I applied value function iteration to estimate the optimal value function given the world model estimates
- finally, I took the greedy policy wrt to the obtained value function in order to create the RL agent
After a number of iterations I was able to get to the following results.