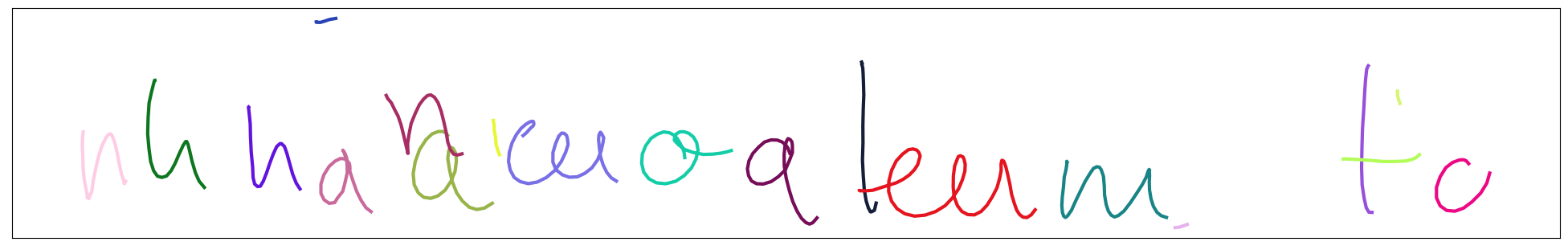
Introduction
It was quite an exciting project for me to reimplement part of the awesome handwriting generation paper from Alex Graves (2015). I picked it because I wanted to learn a new (for me) application of RNNs that gave really fun results, and it was also my first bigger-size project with Pytorch, which was quite enjoyable overall.
I liked Pytorch easy installation process with my GPU and pip, using the Pytorch decision matrix. Besides, the interface and the dynamic nature of the NN graphs made it a very familiar environment for me since it just felt like coding with numpy, which I know quite well through my scientific computing work (e.g. in pvfactors).
An important note also is that I only focused on the unconditional generation part, but I'll update my code with the conditional generation section as soon as I can!
Content
The most exciting part for me reading this paper was the idea of using not just a neural network, but a recurrent neural network in order to estimate the parameters of a mixture of gaussians. I found this quite powerful, because while neural networks with sum of square loss functions end up estimating the expected value of a response conditioned on features :
In this paper the idea was to estimate the whole distribution of like presented in the Mixture Density Networks paper from Bishop et al (1994), while keeping track of history.
Also, since the idea of the paper is to do generation of handwriting offsets, there's no concept of label here. We're modeling at different timesteps instead.
Such that roughly speaking, we're modeling:
where we estimate and using the recurrent neural network, the value as input, but also the encoded past history saved as a "hidden state" in the RNNs, .
It is important to note that the terms do not represent weights, but rather the probability that a Gaussian with index within the Mixture of Gaussians is selected for the given timestep . So they form a multinomial distribution at a given timestep .
For handwriting generation, the additional parameter we're modeling is whether or not the next pen offset is lifted or not (when the pen is down it is drawing, otherwise it just moves to a different location on the canvas). This can be simply modeled by a bernouilli distribution with probability , such that (assuming conditional independence between the next offset value and the lift of the pen):
In the end, the final goal during training is to simply minimize the negative log likelihood from this probability function, summed over all the timesteps in a writing sequence (or a strokeset):
You've probably noticed the cross-entropy loss term added to the loss function and used for general binary classification tasks.
Challenges
I actually struggled quite a bit before I was able to obtain good looking results. What unblocked me was a concept actually described in the paper, that I thought was minor at first, but which ended up making a big difference. It's the idea of adding a "bias" term during generation. The concept is quite simple, by adding a bias term at the right place in the equations for generating data, it is possible to generate offsets the are closer to the mean of the calculated distributions. This allows to avoid unlikely but very detrimental offset occurences when sampling from the mixture of gaussians.
I also learned a lot by reading other projects on how to transform the data to make it look more uniform and cleaner; for instance on how to align all the writing sequences so that it's not slanted anymore. And I also got a lot of insight on how to create and handle batches of handwriting sequences for training and generation.
Results and final notes
Here are some of my results:
- without any alignment correction on the training data
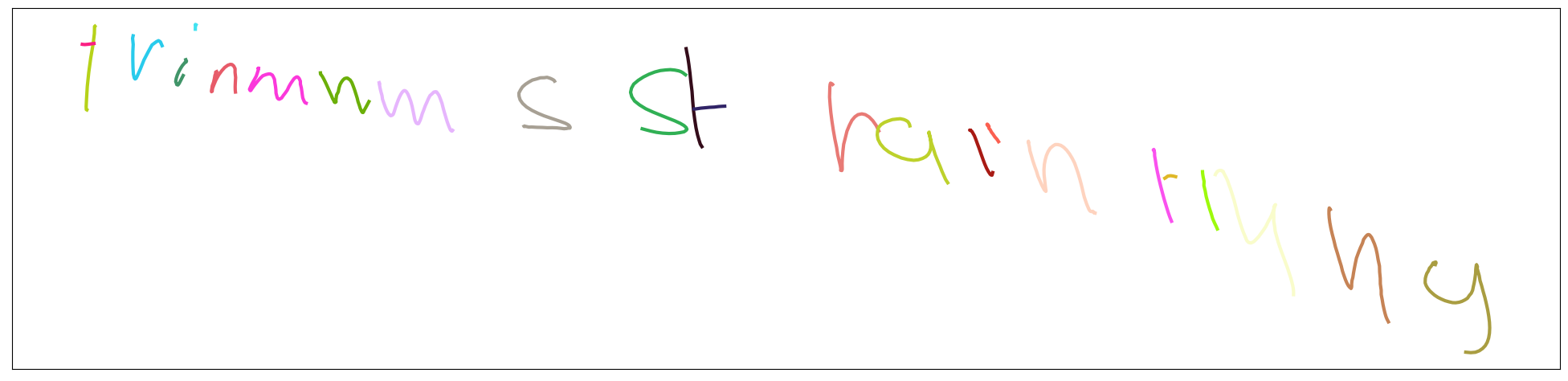
- after applying an alignment transformation on the training data:
I hope you find this work useful or at least interesting! You can find the code on Github.