
Introduction
In a previous post, I described my implementation in pytorch for handwriting generation, following [1] . This was a fun project, but there was a big piece of that paper that I left out and that I was hoping to get back to at some point, and that’s handwriting synthesis.
The difference between handwriting generation and synthesis, is that in the former, the handwritten text is generated without any conditioning. Or in other words, the pen is moving freely without any particular goal. It’s very similar to what LLMs like ChatGPT do, just generating words based on previous words. But in the synthesis case, the handwriting is conditioned on a sequence of characters that the pen will try to write. It’s just like when we, as humans, handwrite anything: we have a mental picture of the text we want to write, and we move our pen to produce a sequence of strokes that will represent the characters we have in mind.
In deep learning terms and as described in [1], handwriting generation can be achieved with RNNs to create a decoder architecture that sequentially generates strokes, keeping some memory of previous actions. And from the same paper, we can see that handwriting synthesis can be achieved with an RNN-based encoder-decoder architecture for sequence-to-sequence modeling, where the input sequence to the encoder is the sequence of text characters, whose embeddings would be passed to the decoder to generate a corresponding handwriting.
Here is the diagram used in [1] to describe the RNN synthesis architecture. The model uses LSTMs with peephole connections that pass concatenated hidden states from multiple upstream layers to the downstream layers at each time step. We can also note that it inserts a “soft window” after the hidden layer 1.
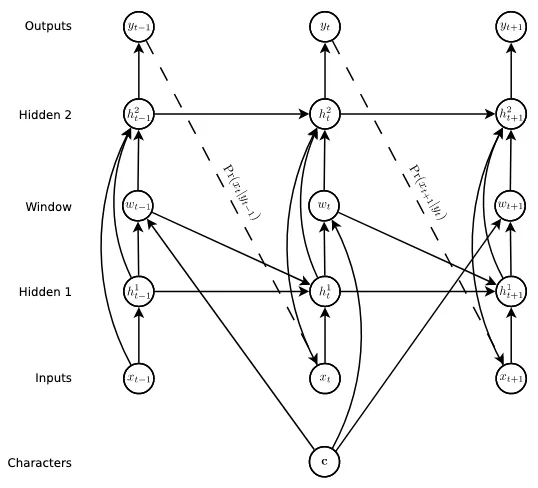
The “soft window” mechanism is a way to bring the RNN layers attention to specific characters at each time step. For instance in the example task of handwriting the character sequence “hello”, the network will first put more weight on the first “h” character, and as it outputs strokes and “time” passes, its attention will shift its weights to the following characters, so next would be “e” in this example.
In [1] , a mixture of K Gaussian functions is used for the soft window, using the following formulation; for a length U character sequence c and a length T data sequence x, the soft window into c at timestep t ( ) is:
where is the window weight of the character in the sequence c, at timestep t. Intuitively, parameters will control the importance of each of the K window terms, will control the width of each window, and their locations.
Lastly, it’s important to understand how these parameters are estimated in the RNN architecture. At each time step, the first RNN layer will output a hidden state from which the soft window parameters will be derived, as follows:
There are a few things to note:
- all of , , and are strictly positive values
- depends on its value at the previous time step
- can therefore only increase
So this means that the soft window location can only slide its attention to the right in the sequence of characters c, which is a very useful built-in property for the task of handwriting synthesis, as we generally write characters one at a time without coming back to previous characters - although it can happen that we come back to previous characters for instance to cross some t’s, or add dots to i’s, but that’s generally rare.
Contributions
In this day and age, the transformer architecture is used for all sorts of things. But at the time of this writing, and after searching hard, I was not able to find an open-source implementation of handwriting synthesis that was based on transformers, curiously. So I decided to do it.
In the process, I quickly realised that the soft window mechanism described above works for RNNs, but it cannot be used as-is with transformers because of the fact that relies on its previous value , and that cannot be achieved with transformers because of how they compute sequential values in parallel, and not sequentially like RNNs.
The contributions of this work are as follows:
- a novel formulation of the soft window mechanism adapted to transformers
- an open-source implementation of handwriting synthesis using an encoder-decoder transformer architecture with this novel soft window attention mechanism, which I call the “soft window transformer”.
Soft window transformers
Because of the sequential nature of the calculation of terms, with dependence on previous terms, the soft margin calculation cannot be used as-is with transformers. But it is possible to update the calculation and keep the same wanted behaviour.
As show in the diagram below, by passing the terms through a causal self attention layer (self attention layer with a causal mask), we can create some time dependency on the calculation of these terms where each term will depend on all previous timesteps. Then applying an exponential allows us to obtain only positive values. And then the final transformation is a simple temporal cumulative sum, which allows the final to be only growing with time, thus essentially shifting the soft window write with respect to the encoded character sequence , which is the same behaviour we had with the RNN soft window mechanism.
The operations of the other terms and are the same as with RNNs.

With this implementation of the soft window transformer, we obtain handwriting synthesis results which are visually really good and readable. They are close in quality to the implementation in [1] using an RNN decoder and the original soft window mechanism.
See images synthesis results below.



But the current results are not perfect. The new soft window attention with transformers sometimes skips some letters, or the model struggles with certain combinations of letters. There could be multiple reasons to that; too short training (took a whole afternoon on an old RTX 2700), too little data, or model size too small.
For instance when trying to plot “new soft window”, we can see that the last “w” is not correct.

But all in all, the results are quite promising for a first try, and there are many things to try to tweak to make it work better.
Next steps
In the future, I would like to perform a more quantitative assessment of the soft window transformer performance not only for handwriting synthesis, but also other sequence-to-sequence tasks such as audio transcription, etc. It would be interesting to benchmark it against other techniques like [2] .
I would like to also try to improve the results by tweaking some of the hyperparameters I mentioned above.
If you made it this far, I hope you enjoyed this read! You can try it yourself here.

References
[1] A. Graves, “Generating Sequences With Recurrent Neural Networks,” Jun. 05, 2014, arXiv: arXiv:1308.0850. doi: 10.48550/arXiv.1308.0850.
[2] X. Ma, J. Pino, J. Cross, L. Puzon, and J. Gu, “Monotonic Multihead Attention,” Sep. 26, 2019, arXiv: arXiv:1909.12406. doi: 10.48550/arXiv.1909.12406.
Citation
If you find this work useful, please cite it as:
@article{anomam2025softwindowtransformers,
title = "Soft window attention with transformers for handwriting synthesis",
author = "Abou Anoma, Marc",
journal = "blog.anomam.com",
year = "2025",
url = "https://blog.anomam.com/posts/2025-06-18-soft-window-transformers-hw-synthesis"
}